QQ咨询
QQ咨询 阿里旺旺
阿里旺旺 #skype#
#skype#
利用 Amazon CloudWatch 监控 GPU 利用率
深度学习需要进行大量的矩阵相乘和向量运算,而 GPU (图形处理单元) 可以并行处理这些运算,因为 GPU 拥有数以千计的核心。Amazon Web Services 为您提供的 P2 或 P3 实例非常适用于运行深度学习框架,如 MXNet,该框架强调加速部署大型深度神经网络。
数据科学家和开发人员在微调网络时,希望优化其 GPU 的利用率,以使用最适当的批处理大小。在这篇博文中,我将向您展示如何使用 Amazon CloudWatch 指标监控 GPU 和内存的使用情况。至于 Amazon 系统映像 (AMI),我们建议您的实例使用 Amazon Deep Learning AMI。
要监控和管理已启用 GPU 的实例,目前常见的有益做法是使用 NVIDIA 系统管理接口 (nvidia-smi),这是一个命令行实用程序。用户可以利用 nvidia-smi 查询 NVIDIA GPU 设备的 GPU 利用率、内存消耗情况、风扇使用情况、功耗以及温度信息。
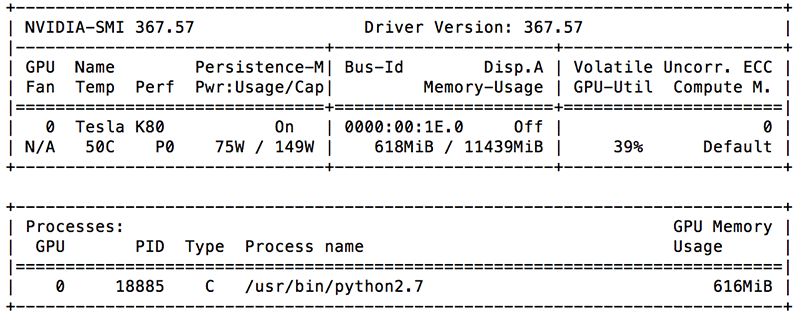
由于 nvidia-smi 的基础是 NVIDIA Management Library (NVML),所以我们可以使用这个基于 C 的 API 库捕捉相同的数据点,并作为自定义指标发送给 Amazon CloudWatch。如需了解有关此库的更多信息,请转至参考手册。在这篇博文中,我们将使用此库的 Python 包装程序 pyvnml。
Amazon CloudWatch 可以非常出色地监控您在 EC2 实例上的工作负载,无需设置、管理,也无需为它扩展系统和基础设施。默认情况下 CloudWatch 可提供 CPU 利用率、磁盘读取操作、磁盘写入操作、网络输入和网络输出等指标。(点击此处了解适用于您的实例的完整指标列表)
除了提供这些指标,我们还能够使用 API、软件开发工具包或 CLI 通过 Amazon CloudWatch 自定义指标推送我们自己的数据点。我们将使用 Python Boto3 软件开发工具包。
您可以在 Amazon CloudWatch 中创建自定义控制面板来查看您的资源。您还可以为您的指标创建警报。还有许多可以与 CloudWatch 结合使用的功能和服务。如果您希望访问并存储 Amazon EC2 实例生成的日志,可以使用 Amazon CloudWatch Logs。此外,Amazon CloudWatch Events 可以为您提供描述 AWS 资源变化的数据流,例如,如果有人试图在模型训练完成之前终止您的实例,您可以收到提醒。
立即设置
默认情况下,已对您的实例启用基本监控。我们会启用详细监控,Amazon EC2 控制台将以 1 分钟为间隔显示实例的监控状态。
注意:基本监控是免费的,但详细监控会收取费用。新客户和现有客户每月可免费获得 10 个指标、10 个警报,以及 100 万个 API 请求 (包括 PutMetricData)。
鉴于您的实例已运行在 Deep Learning AMI 之上,我们需要创建一个 IAM 角色,为您的实例授权,使其能够向 Amazon CloudWatch 推送指标。我们需要根据文档中的描述创建一个 EC2 服务角色。请确保您的角色允许以下策略。
接下来在您的实例上下载 Python 代码。我们将使用此脚本,将 GPU 使用情况、内存使用情况、温度和电源使用情况作为自定义 CloudWatch 指标进行推送。
安装必要的程序包,以使用代码:
请确保根据您的工作负载更改命名空间和间隔。您还可以选择更改 store_reso,使用间隔缩短至 1 秒的高精度指标,从而更精确地了解 GPU 的使用情况。
默认情况下,这些是顶部的参数:
运行脚本:
训练完成后按 ctrl-z 或 ctrl-c 停止脚本。
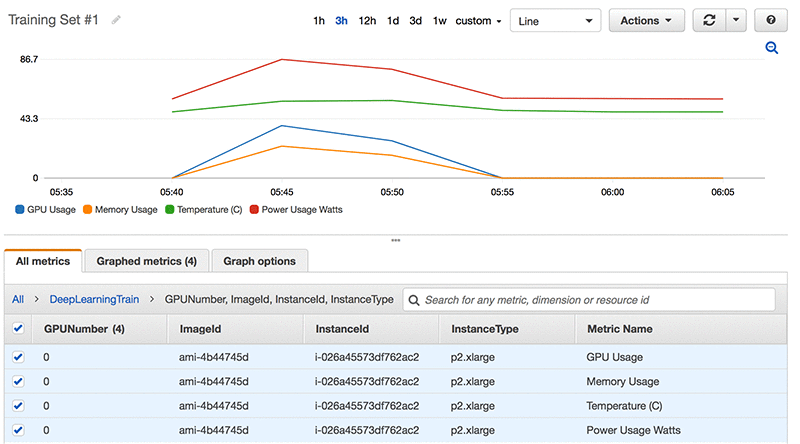
以下是一个正在运行的训练的 Amazon CloudWatch 视图示例。请观察在计算过程中所有指标是如何互相关联的。
结论
在这篇博文中,我将提供一种简便的方法,它不仅可以监控 GPU 利用率,还可以监控您的 NVIDIA GPU 设备的内存、温度和电源使用情况。如果您要添加其他自定义指标或删除自定义指标,可以修改我提供的代码。接下来,就像我们在介绍时提到的,要尝试为您的指标创建 CloudWatch 警报。例如,您可以设置 Amazon SNS 通知,在模型训练期间,GPU 利用率低于 20% 即向您发送电子邮件。
补充阅读
开始使用 AWS Deep Learning AMI 进行深度学习!